FlashMoE is the first fully fused Distributed MoE system that achieves high tensor core utilization by eliminating kernel boundaries and enabling fine-grained overlap of communication and computation. We provide high-performance single- and multi-node EP inference and work seamlessly with CUDA graphs. See paper here.
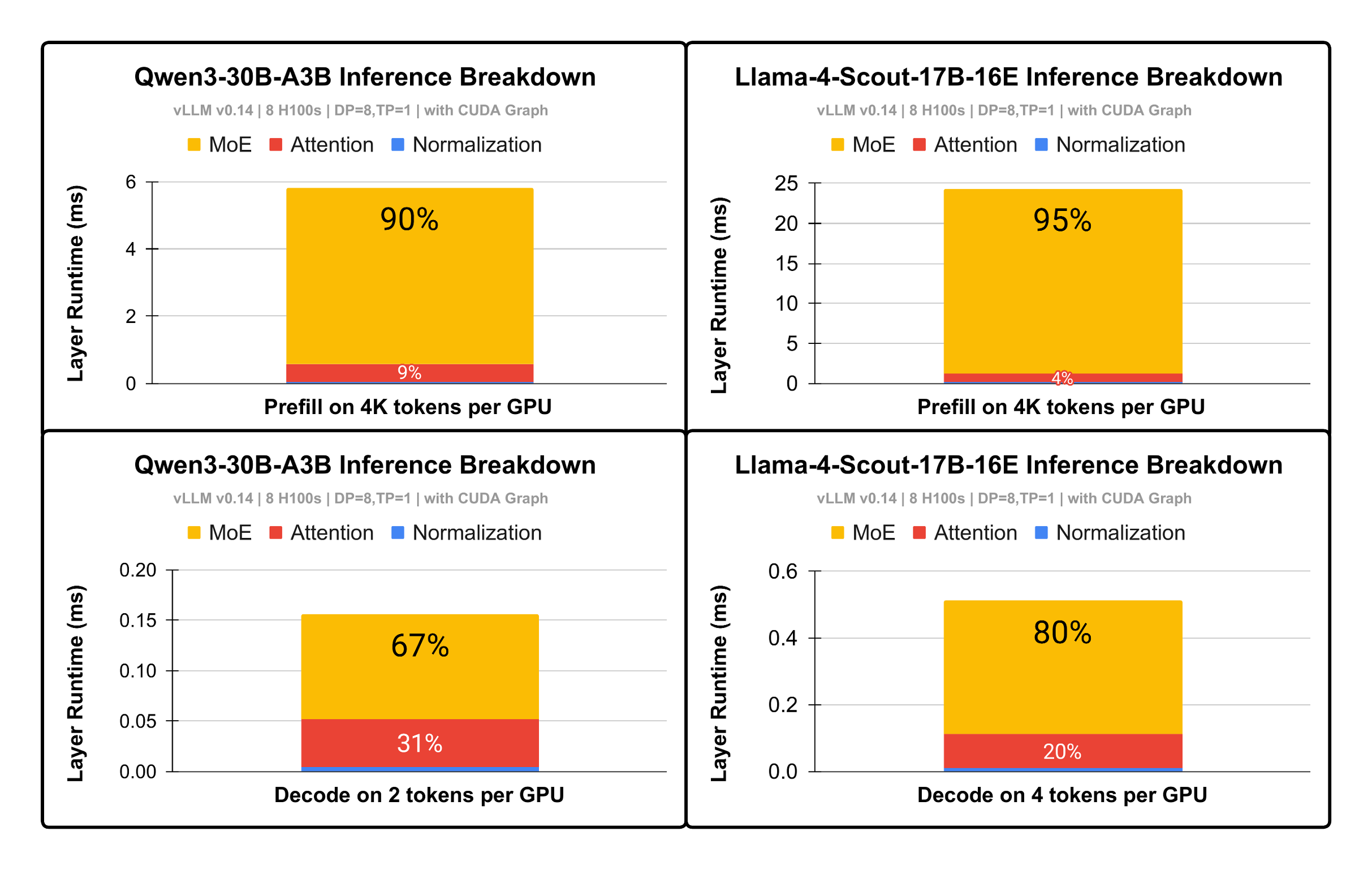 Figure 1: Opportunity. MoE takes 67%-95% of inference runtime. |
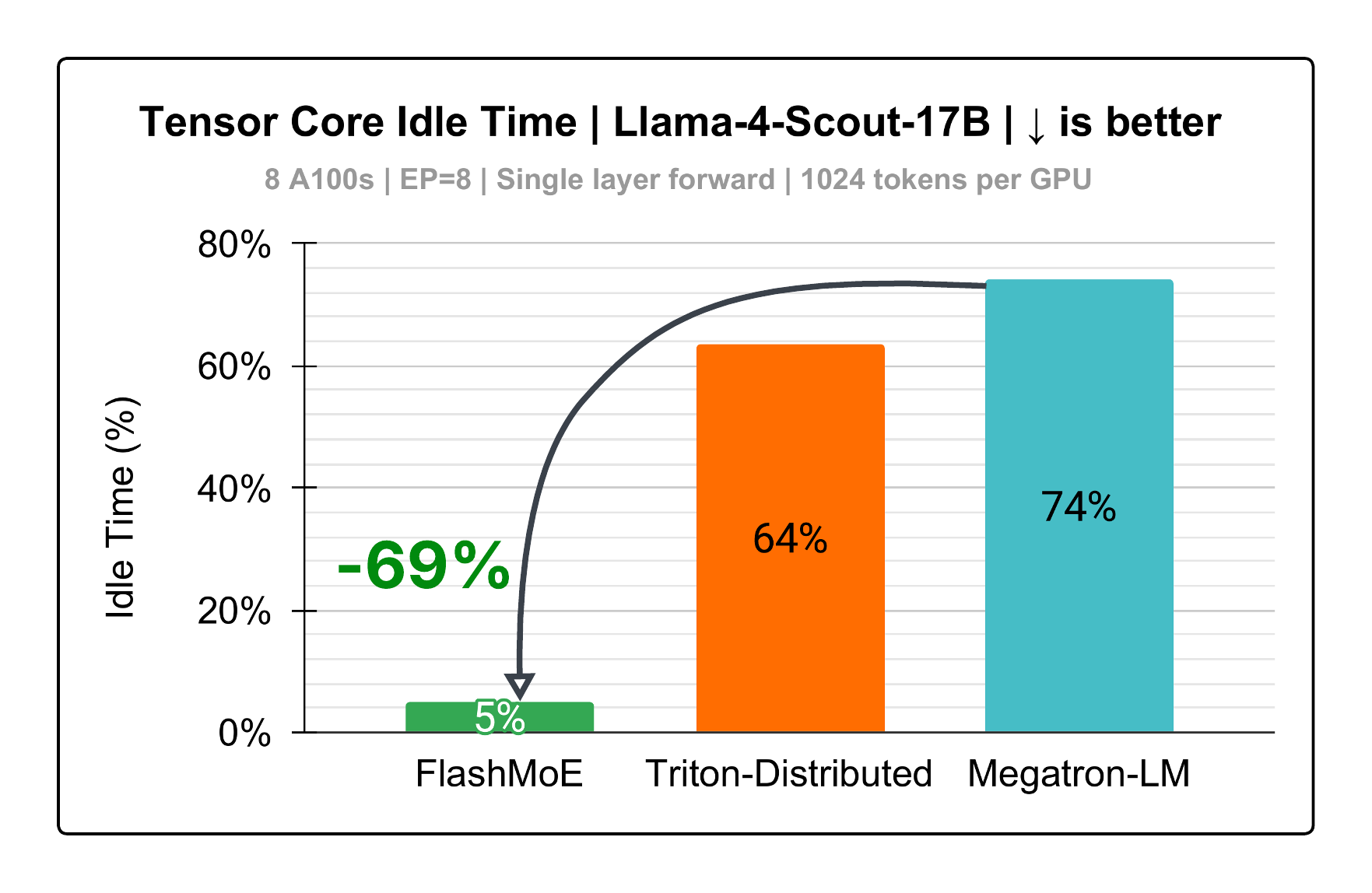 Figure 2: Tensor core Utilization. y-axis is percentage of MoE runtime that tensor cores are inactive. |
Distributed Mixture-of-Experts (DMoE) is an extremely demanding workload, both compute- and communication-intensive, accounting for up to 95% of total inference runtime (Figure 1).
This makes DMoE the primary bottleneck in distributed inference and a critical target for optimization.
However, existing implementations leave significant performance untapped, achieving only 26% tensor core utilization (Figure 2).
We identify three key sources of inefficiency:
- Exposed communication on the critical path
- Straggler-induced delays from load imbalance
- System overheads from dynamic token routing (e.g., metadata management, inputs preprocessing for compute operators like GroupedGEMM)
As a result, GPUs spend the majority of time stalled, with only 26% of runtime utilizing tensor cores.
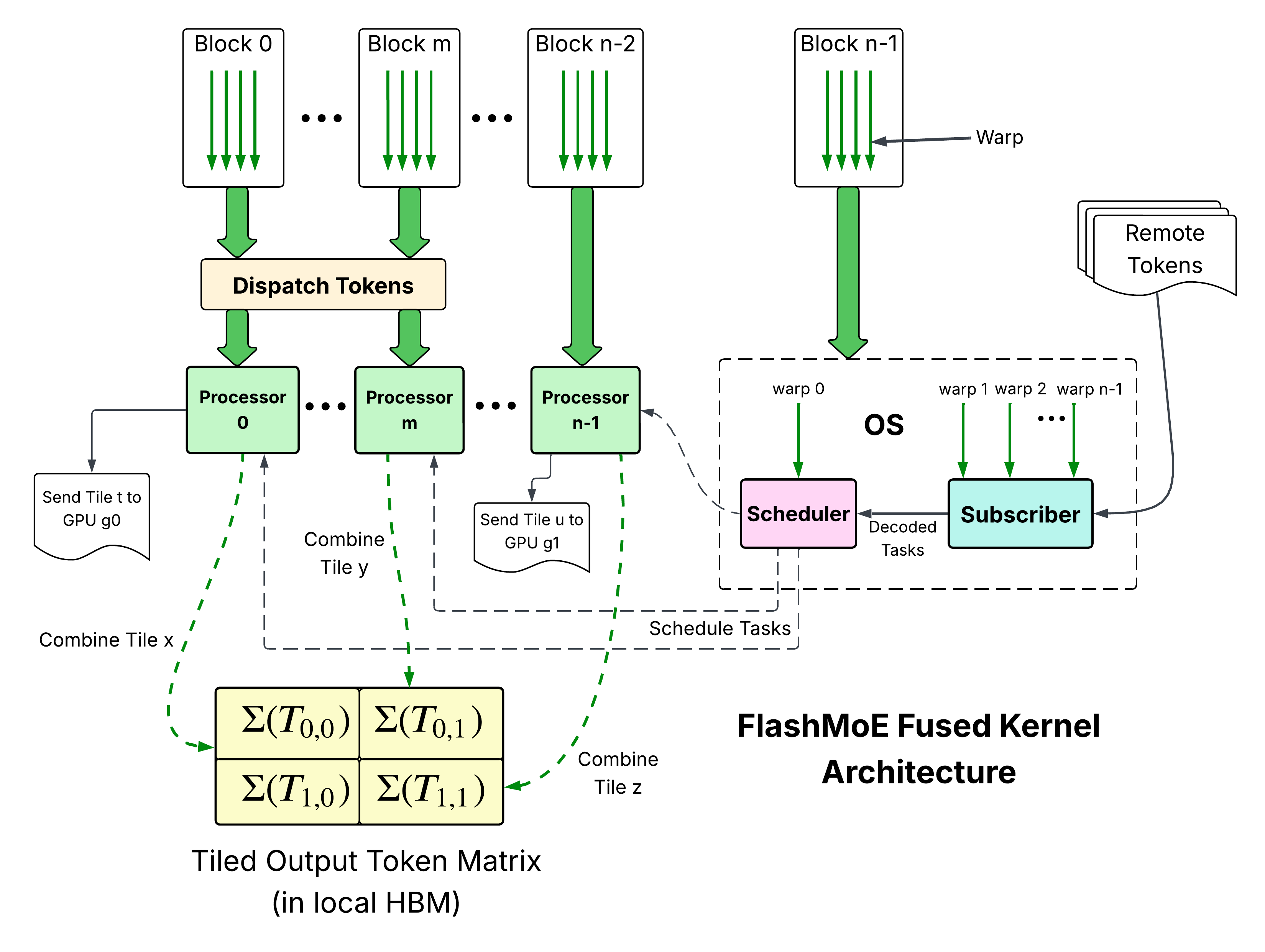
Figure 3: FlashMoE Architecture
We address these inefficiencies through complete kernel fusion, enabling:
- Fine-grained overlap of communication and computation at tile granularity
- Latency hiding of preprocessing and system overheads via SM specialization
- Exploitation of task locality at scale, allowing SMs to execute ready tasks out-of-order, minimizing tensor core idle time and boosting SM utilization.
In contrast, existing implementations rely on tens to hundreds of serialized kernels, enforcing strict execution order and limiting task locality.
This results in unnecessary stalls—for example, during collective synchronization (AllGather, ReduceScatter, AllToAll), where GPUs idle waiting for stragglers instead of executing independent compute tasks.
We present FlashMoE (Figure 3), the first fully fused Distributed MoE system.
FlashMoE is a high-throughput, portable system that fuses:
- MoE Dispatch
- Expert Computation (Gated MLP or standard MLP)
- MoE Combine
into a single tile-pipelined persistent kernel.
At its core, FlashMoE embeds an Operating System within the kernel, enabling concurrent scheduling and execution, thereby hiding system and communication latency.
FlashMoE is built from the ground up in CUDA C++, with selective inline PTX. It leverages:
- cuBLASDx for device-side high-performance compute
- NVSHMEM for asynchronous, device-initiated communication
- CCCL and CUTLASS for critical infrastructure
We support
- SM70 and above GPUs. Boosting compute performance for Hopper and Blackwell is on the roadmap.
- NVLink and multi-node RDMA (EFA, IBGDA, libfabric as NVSHMEM supports).
- FP16, BF16, FP32 (TF32) and FP64. FP8 and even lower precision types are on the roadmap (we welcome contributions!)
- CUDA toolkit
- C++20
- ninja (
sudo apt install ninja-build) - CMake (>= 3.28)
- GPU architecture of at least SM 70.
- A P2P GPU interconnect (NVLink, some PCIe and GPUDirect RDMA). NVSHMEM will fail if this criterion is not met.
- Download from here and save in
<your_directory>, e.g~/.local.
- Install as directed here.
export NVSHMEM_LIB_HOME=/usr/lib/x86_64-linux-gnu/nvshmem/<12 or 13>. #Do confirm this directory exists!
export MATHDX_ROOT=<your_directory>/nvidia-<...>/mathdx/yy.mm/
export CMAKE_PREFIX_PATH=$NVSHMEM_LIB_HOME:$MATHDX_ROOT:$CMAKE_PREFIX_PATH
export LD_LIBRARY_PATH=$NVSHMEM_LIB_HOME:$LD_LIBRARY_PATH👉 Tip: add the above exports to your
.bashrc
pip install flashmoe-py[cu12] # or cu13See quickstart.py for a complete example, the below is just a showcase.
import flashmoe
if __name__ == "__main__":
# Llama4-Scout-17B-16E shapes
# model description which flashmoe.initialize uses to JIT compile the kernel
tokens_per_rank = 1024
token_dim = 5120
ffn_size = 8192
num_experts = 16
k = 1
mlp_type = flashmoe.MLPType.GATED # Gated MLP
data_type = flashmoe.DataType.BF16
act_type = flashmoe.ActivationType.SILU
init_args = flashmoe.InitArgs(...)
flash_handle = flashmoe.initialize(init_args)
router_handle = flashmoe.router.initialize(init_args)
router_forward_args = ...
# single kernel for GEMM + Softmax + topk selection
flashmoe.router.forward(router_handle, flash_handle, router_forward_args)
flashmoe_forward_args = ...
# single kernel for Dispatch + Experts + Combine
flashmoe.forward(flash_handle, flashmoe_forward_args)
# call finalize
flashmoe.finalize(flash_handle)
flashmoe.router.finalize(router_handle)We suggest running these to verify that you meet all installation requirements.
torchrun --nproc_per_node=<number of GPUs> quickstart.py --torch-initpip install mpi4py
mpirun -n <number of GPUs> python3 quickstart.pyGetting this to work would be dependent on the launcher in your cluster. Below, we suggest some launch recipes. Use what works for you.
# SLURM with libfabric (tested)
export NVSHMEM_REMOTE_TRANSPORT=libfabric
export NVSHMEM_LIBFABRIC_PROVIDER=... # efa,cxi,or verbs
export NVSHMEM_DISABLE_CUDA_VMM=1
export NVSHMEM_BOOTSTRAP=MPI
srun -N <number of nodes> -n <total number of gpus> \
--ntasks-per-node=<gpus per node> --gpus-per-task=1 --gpu-bind=closest python3 quickstart.py# torchrun with Connect-x NICs (not tested)
export NVSHMEM_IB_ENABLE_IBGDA=true
torchrun \
--nproc_per_node=<number of GPUs> \
--nnodes<...> \
--rdzv_endpoint=<master address, like hostname of rank 0> \
--rdzv_backend=c10d \
--rdzv-id=<some id, like 123456789> \
--node_rank=<...> python3 quickstart.pyAdd the following to your CMakeLists.txt
set(CPM_SOURCE_CACHE
"${CMAKE_CURRENT_SOURCE_DIR}/cmake/cache"
CACHE PATH "Shared CPM source cache"
)
set(CMAKE_CUDA_ARCHITECTURES "native") # or your own architecture
#...
CPMAddPackage(
NAME flashmoe
GITHUB_REPOSITORY osayamenja/flashmoe
GIT_TAG v0.1.2
)
target_link_libraries(app PRIVATE flashmoe::flashmoe)
FlashMoESetRDC(app)
FlashMoEAddOptions(app)and include the header file like below. See csrc/tests/flashmoe.cu for more usage details.
#include <flashmoe/flashmoe.cuh>- Improve MMA for Hopper (WGMMA) and Blackwell (UTCMMA).
- FP8
- Shared experts
- AMD support
- Backward pass
- We measure with the EP+DP parallelism scheme.
- We compare against:
- COMET (MLSys '25) at commit: 19831ca2d820e3e782ed1d15d8b52d0898b78b26
- Megatron-LM at v0.15.3
- Triton-Distributed at commit: 3644f0586d14591c8a43a10aa6b47fe98a95aea7
- We measure a single layer's execution only.
- For every model we evaluated,
we use model shapes and data types as defined in its corresponding
config.jsonon HuggingFace. - We do not execute any shared experts.
👉 On frontier MoE models, FlashMoE gives up to 5x speedup and 69% increase in tensor core utilization compared to SOTA baselines.
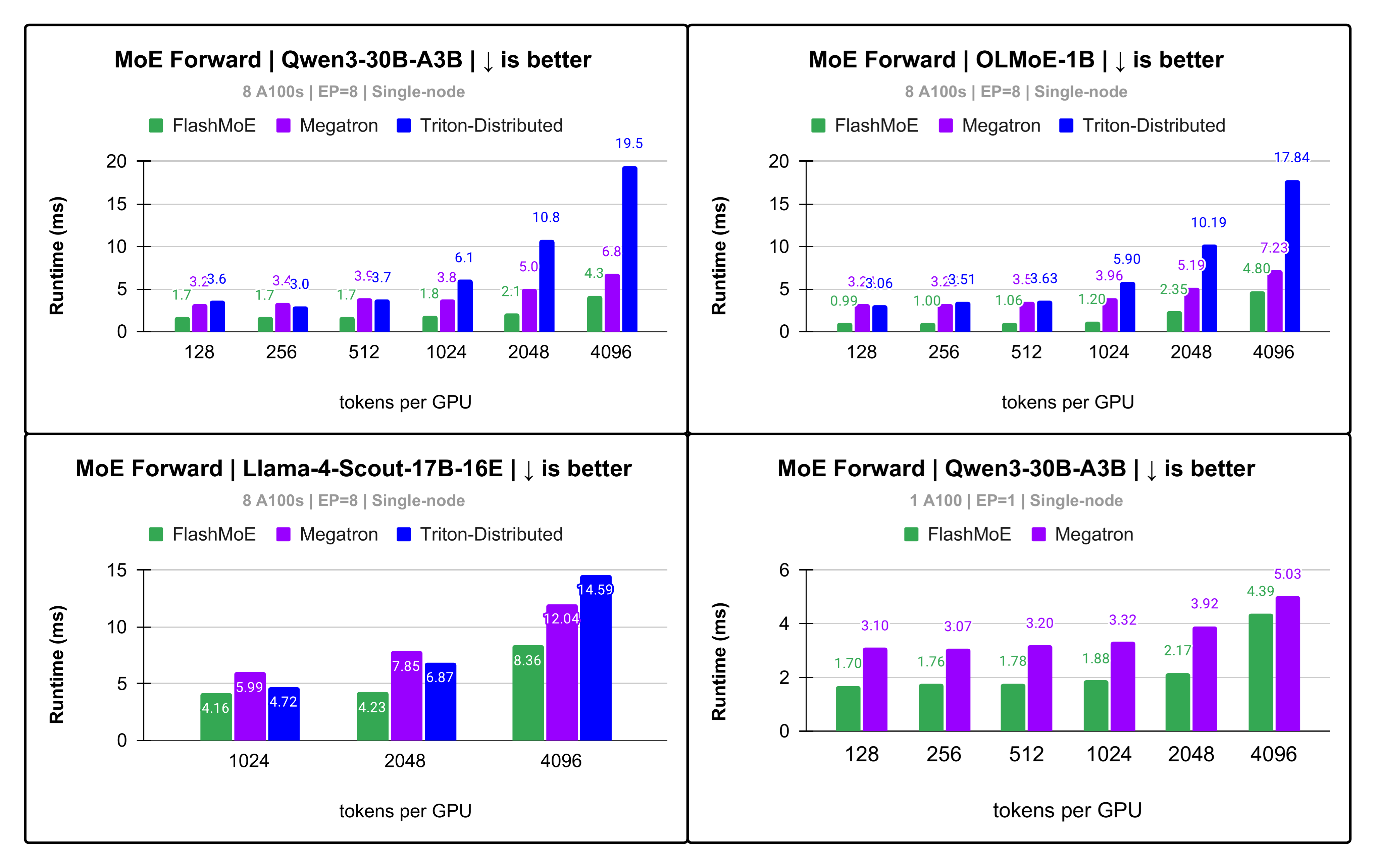
Figure 4: Up to 5.1x faster MoE layer runtime on Qwen-30B with single-node EP
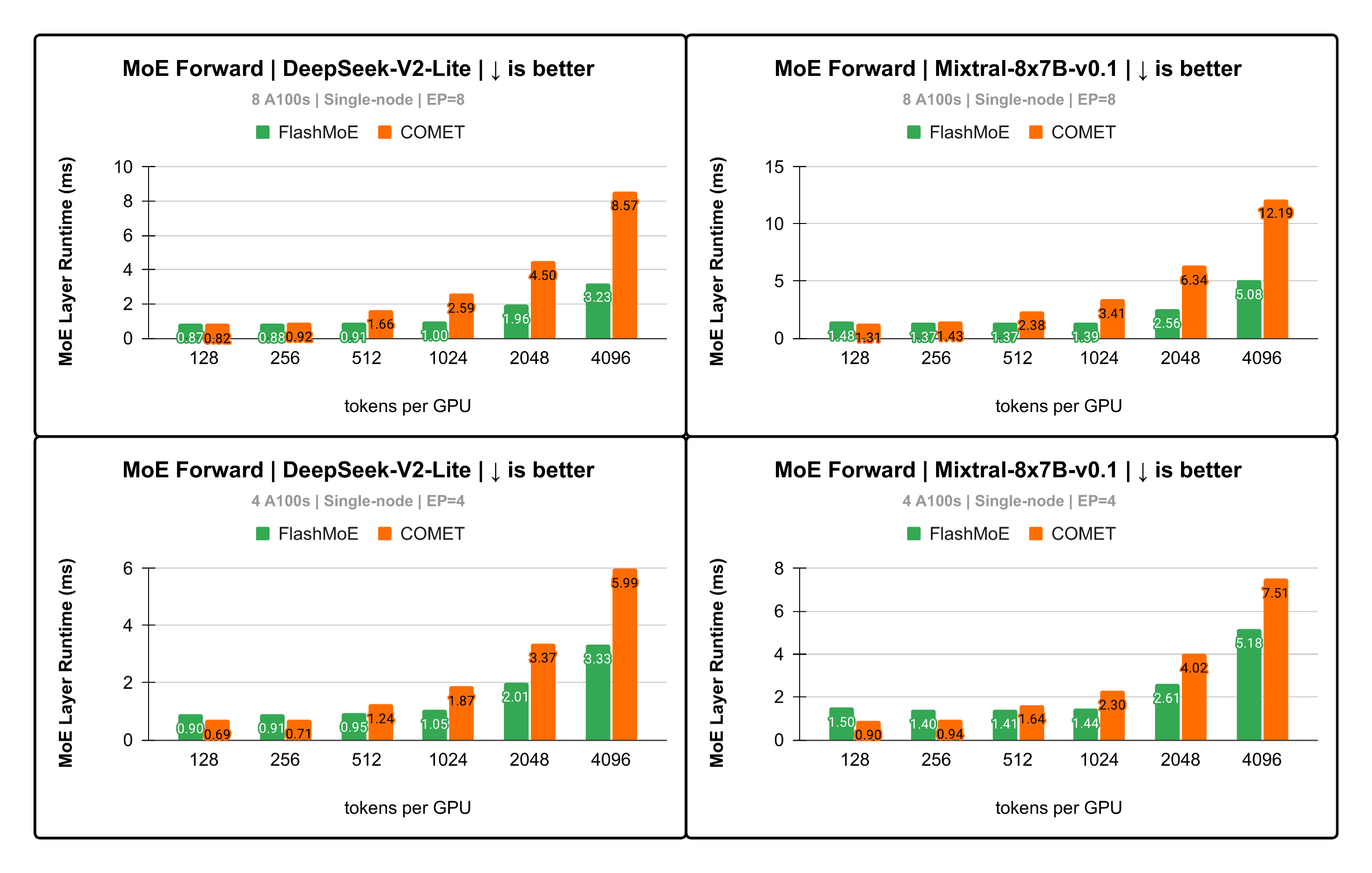
Figure 5: Up to 2.6x faster runtime DeepSeek-V2-Lite
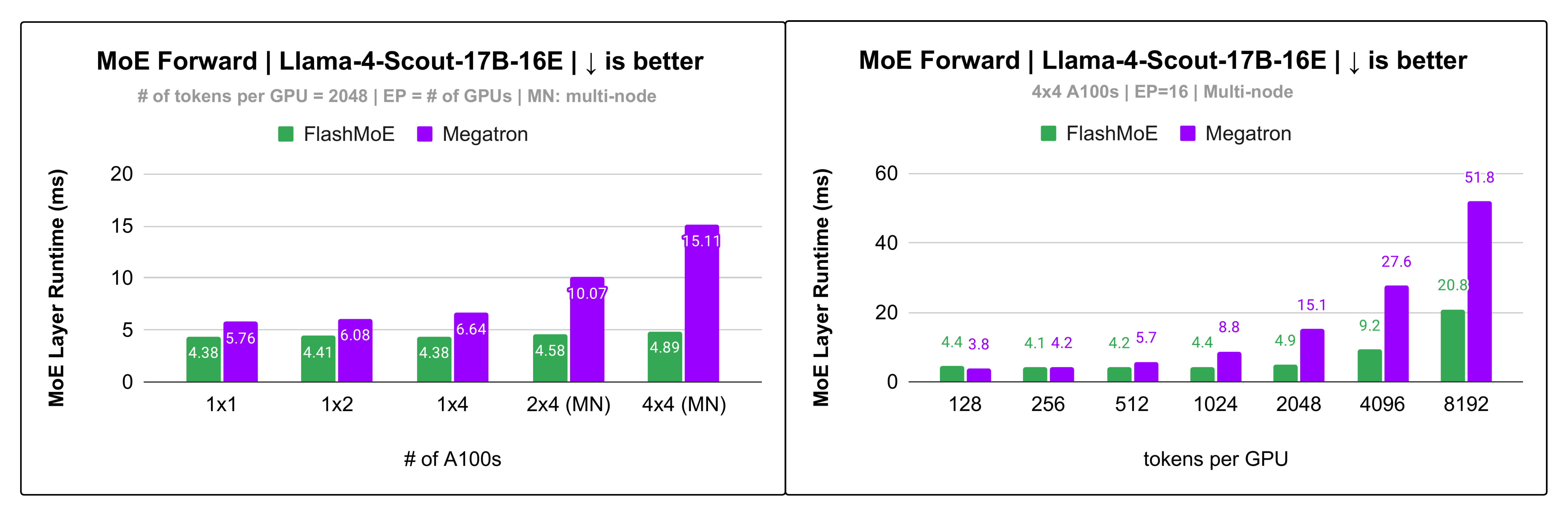
Figure 6: Up to 3x speedup on Llama4-Scout for multi-node EP!
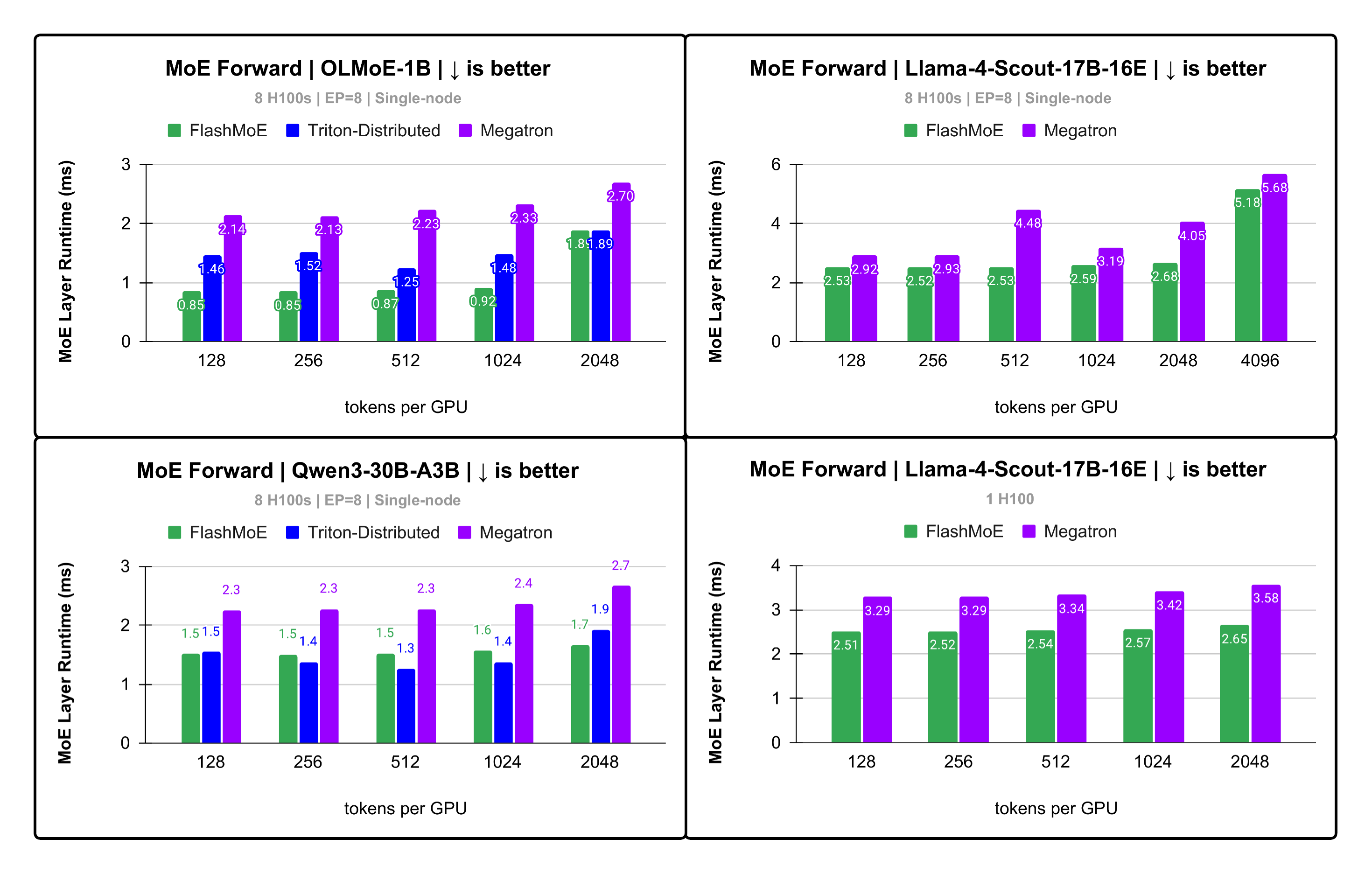
Figure 7: Up to 2.5x speedup on H100s.
cd csrc
mkdir cmake-build-release && cd cmake-build-release
cmake -DCMAKE_BUILD_TYPE=Release -Wno-dev -G Ninja -S.. -B.
cmake --build . --target testFlashMoE --parallel
export NVSHMEM_BOOTSTRAP=MPI
mpirun -n <world> ./testFlashMoE <num tokens per rank> <token dim> <ffn dim> <num experts total> <top k>The codebase integrates well with CLion: open the project at csrc.
We welcome them! Submit a PR!
Super grateful to the amazing folks behind
- cuBLASDx
- CUTLASS
- NVSHMEM
- CCCL
This work would not have been possible without the critical building blocks they provide.
If you can, please cite as below:
@misc{aimuyo2025flashmoe,
title={FlashMoE: Fast Distributed MoE in a Single Kernel},
author={Osayamen Jonathan Aimuyo and Byungsoo Oh and Rachee Singh},
year={2025},
eprint={2506.04667},
archivePrefix={arXiv},
primaryClass={cs.DC},
url={https://arxiv.org/abs/2506.04667},
}