This project focuses on classifying user-generated comments into multiple categories using a structured machine learning pipeline.
The workflow covers:
- 🔍 Data understanding
- 🧹 Preprocessing
- 📊 Exploratory analysis
- 🧠 Feature engineering
- 🤖 Model training & evaluation
- Accurately classify comments into predefined categories
- Handle imbalanced class distribution
- Build a model that generalizes well
- Removed irrelevant features
- Handled missing values
- Standardized dataset for modeling
- 📊 Univariate Analysis: feature distributions, outliers, and descriptive statistics
- 🔗 Bivariate & Multivariate Analysis: relationships between features and target variable
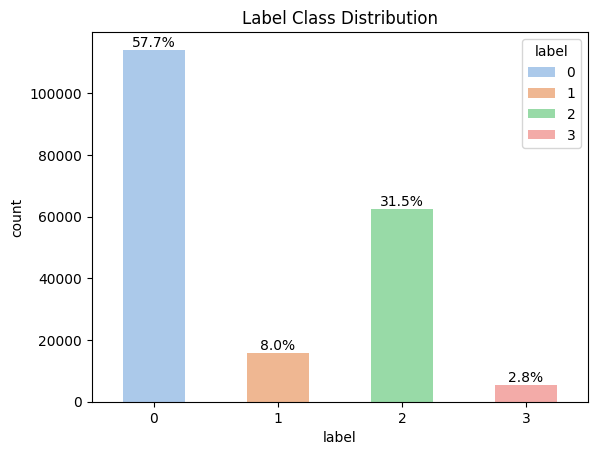
- ⚖️ Class Distribution Analysis: identification of class imbalance
- 📝 Text Analysis: review of sample comments and linguistic patterns
- ☁️ WordClouds: top words across entire dataset and across individual classes
-
📝 Text-based features: comment length, word count, average word length
-
⏱️ Temporal features: extracted hour and month
- Applied sine-cosine transformation to capture cyclic patterns
-
🔁 Zero-inflated features
- Identified features with excessive zeros
- Converted into binary indicators to capture presence/absence
-
📉 Handling skewness
- Evaluated log transformation and Yeo-Johnson transformation
- Yeo-Johnson selected as it reduced skewness more effectively
-
🔍 Feature Selection & Comparison
- Used Mutual Information (MI) for feature importance
- Compared raw vs transformed features separately
- Transformed features slightly outperformed and were retained
-
🔗 Final Feature Set
- Transformed numerical features
- Word-level TF-IDF
- Character-level TF-IDF (
char_wb)
- Built TF-IDF features using both word-level and character-level (
char_wb) analyzers
- Tuned n-gram range, min_df, max_df, and sublinear TF scaling
- Captures semantic and contextual word patterns
-
Tuned n-grams, min_df, and max_df
-
Captures subword patterns and improves robustness to noisy text
-
🔧 Both vectorizers were independently tuned and optimized
-
📊 Final feature space consisted of ~125K TF-IDF features
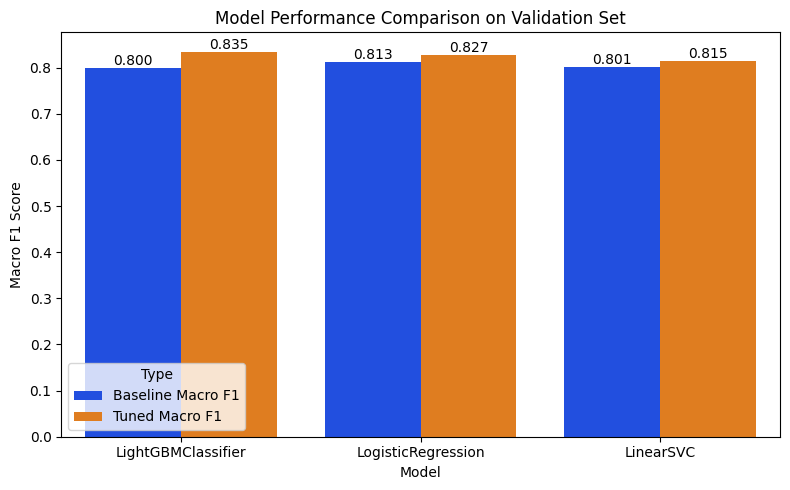
Models were trained under a consistent pipeline and systematically tuned:
- Logistic Regression → tuned using RandomizedSearchCV (regularization, tolerance, class weights)
- Linear SVM (LinearSVC) → tuned for regularization and class weights
- LightGBM Classifier → manually tuned across multiple parameter combinations
-
Evaluated model performance using classification report, confusion matrix, and precision-recall (PR) curves
-
📊 Classification Report
- Analyzed precision, recall, and F1-score per class
- Helped identify performance gaps, especially in minority classes
-
🔁 Confusion Matrix
- Provided a clear view of class-wise predictions and misclassifications
- Useful for understanding where the model was confusing similar categories
-
📉 Precision-Recall (PR) Curves
- Focused on minority classes, where performance is harder to capture
- Helped analyze the precision–recall trade-off under class imbalance
-
⚠️ ROC Curve not used- Dropped due to large number of true negatives, which can make ROC curves overly optimistic in imbalanced settings
Macro F1 Score
- Accounts for class imbalance
- Treats all classes equally
Macro F1: 0.8350
Macro F1: 0.8344
- Some categories had significantly fewer samples
- Addressed using class weight tuning to penalize minority classes
- Improved recall for minority classes, with a trade-off in precision which was balanced to achieve a good macro f1 score
- Informal language, inconsistencies, and variations
- Improved robustness using character-level TF-IDF
- Numerical features showed strong skewness
- Evaluated both log transformation and Yeo-Johnson transformation
- Yeo-Johnson provided better normalization and was selected
- Used Mutual Information (MI) to evaluate feature importance
- Compared raw vs transformed features
- Transformed features slightly outperformed and were retained
- Linear models performed strongly on high-dimensional sparse features
- Extensive hyperparameter tuning was performed across models
- Trade-off between capturing minority class patterns and risk of overfitting
- Slight overfitting observed on training/validation was intentional to improve Macro F1
- Final model generalized well, with consistent or slightly improved performance on leaderboard data
- Feature engineering significantly improved model performance
- Character-level TF-IDF helped capture minority class patterns more effectively
- LightGBM outperformed linear models by capturing both linear and non-linear relationships
- Focus was on balancing precision and recall, especially for minority classes, under the Macro F1 metric
- 🐍 Core: Python
- 🤖 Machine Learning: Scikit-learn, LightGBM
- 📊 Data Handling: Pandas, NumPy
- 📉 Visualization: Matplotlib, Seaborn, WordCloud
- 🔤 Text Processing: Regex (
re), TF-IDF - 📐 Statistical Transformations: SciPy (
scipy.stats)
├── 23f2005144-comment-classification-notebook.ipynb # Complete workflow
├── submission.csv # Final predictions
└── README.md # Documentation
A structured end-to-end machine learning pipeline for multiclass text classification, with emphasis on:
- Data understanding and comprehensive exploratory analysis
- Advanced feature engineering, including transformations and feature selection
- Robust text representation using word-level and character-level TF-IDF
- Systematic model tuning and comparison across linear and boosting models
- Careful evaluation using class-wise metrics and precision-recall analysis
- The notebook contains full experimentation, including feature comparisons and model tuning
- Evaluation includes classification reports, confusion matrices, and PR curve analysis
- Emphasis is placed on data-driven decision-making and trade-offs at each stage of the pipeline