I am getting unwanted behavior from an AdvancedOcr object where its AcceptedOcrCharacters field has been explicitly defined.
As observable at the bottom of this image, I have defined AcceptedOcrCharacters = "x0123456789ABCDEF"
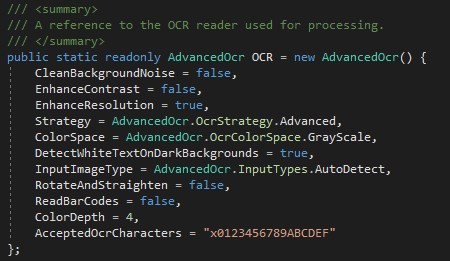
Yet despite this, OCR.Read() is spitting out unwanted results, such as:
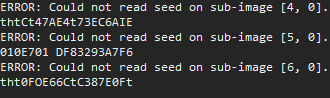
| Expected |
Received |
0xC147AE4173EC6A1E |
thtCt47AE4t73EC6AIE |
0xCE7D1DF83293A7F6 |
010E701 DF83293A7F6 |
0x0F0E66C1C3B7E0F1 |
tht0FOE66CtC387E0Ft |
I expect read errors to occur where two characters may get confused (e.g. B and 8), however I do not expect the return values to have characters that I did not even define as allowed in the first place.
I am getting unwanted behavior from an
AdvancedOcrobject where itsAcceptedOcrCharactersfield has been explicitly defined.As observable at the bottom of this image, I have defined

AcceptedOcrCharacters = "x0123456789ABCDEF"Yet despite this,

OCR.Read()is spitting out unwanted results, such as:0xC147AE4173EC6A1EthtCt47AE4t73EC6AIE0xCE7D1DF83293A7F6010E701 DF83293A7F60x0F0E66C1C3B7E0F1tht0FOE66CtC387E0FtI expect read errors to occur where two characters may get confused (e.g. B and 8), however I do not expect the return values to have characters that I did not even define as allowed in the first place.